
國際政策趨勢
AI晶片為何如此重要(下)

人工智慧的國際競爭正是美中科技戰的主要背景,而在此一競爭中晶片設計與製造能力成為關鍵的戰略資產。美國研究AI政策的智庫Center for Security and Emerging Technology,在今年四月出版一份報告(AI Chips: What they are and why they matter?),說明AI晶片的發展趨勢以及對美國戰略佈局的重要性。台灣在晶片製造能力上舉足輕重,也註定在這場AI國際競爭中扮演關鍵角色,因此這篇報告值得細讀,本網站詳細摘譯了該報告的內容並分上下兩集刊登。
五、AI晶片的蓬勃
AI目前傾向於使用專用晶片的趨勢有兩個重大原因,首先目前半導體的成長重心已經逐漸轉向設計和軟體方面,再來AI相關的應用需要大量使用平行計算,都是AI晶片的優勢。深度神經網路最近讓AI有重大的突破,而這種神經網路使用一種叫做監督式學習的方法,主要需要兩個步驟,訓練和推論,在訓練的步驟經常需要同步執行某些運算很多次,所以就需要一些特製的電路,而AI晶片能把這件事做到極致。
雖然分析師間對於AI晶片的市場的預測差距很大,但他們都一致認為AI晶片的市場會成長得比其他來得快。直到最近已經很少有企業設計如CPU這種通用晶片來主宰市場。他們利用規模經濟來不段的投資新的CPU設計,但摩爾定律的減慢讓這些CPU生產者不再有以前的優勢,目前專用晶片有比較長的生命週期來超過CPU的商業價值。因此,CPU生產者利用經濟規模來投入新產品的優勢已經在消失當中,而這項趨勢讓晶片設計的進入障礙變低了,特別是那些專注於特製晶片的企業。
AI晶片是很常見的特製晶片,而且彼此間有功通的特性,AI晶片比CPU執行更多的平行算算,也把計算的精準度調低但可以減少一個運算中使用的電晶體數目。他們透過把整個AI演算法存在晶片裡加速記憶體的存取,最後AI晶片用的程式語言能夠較有效率的把訓練AI的程式碼轉換到AI晶片上執行。
在通用晶片上往往有些熱門的設計,但AI晶片的種類非常的多,根據不同的應用彼此間設計的差異非常的大,接下來的章節會把這些AI晶片做分類。
AI晶片的種類
AI晶片有三種類別,GPU、FPGA和ASICS。
GPU本來是利用平行運算的設計來處理圖形處理的應用,在2012年,GPU開始越來越常被用於訓練AI,而到2017年已經全面主宰,GPU有時後也可以拿來推論,雖然GPU可以執行很多平行的運算,但他基本上還是被設計用來做通用用途。
最近,特製的FPGA和ASIC在推論上變得特別傑出,ASIC也越來越廣泛的被用於訓連模型。FPGA上有一些邏輯區塊,它們彼此間的交互作用可以由工程師自行設計來幫助特定的演算法,而ASIC則是直接針對電路做特製,通常來說領先的ASIC比FPGA的效率來的好,然而FPGA隨著AI演算法不斷的更新更容易做客製化,在新AI演算法發展的同時ASIC已經慢慢的過時。
訓練的過程比起推論更常用到不同的AI晶片,首先,不同形式的資料和平行化程度可能會影響要使用哪一種晶片,第二,訓練的過程的加速通常都是透過資料處理的平行化,而推論則相反,不過對於某些應用來說,推論也會針對很多資料做平行處理,特別是當任務是要處理很大量的零碎資料的時候。第三,根據不同的應用,效率和速度的重要性是不同的,對於訓練來說,效率和速度同時都是重要的,而對於推論來說,速度通常很重要,例如自動駕駛或者是需要及時處理使用者的需求,和即時的資料分類。但是推論對於速度的需求有個天花板,例如在APP上,推論的速度不需要快過使用者的反應速度。
推論用的晶片通常需要較少的研發者,因為他們對於計算優化的需求較少,而且ASOC比起GPU和FPGA需要較少的研發者,因為ASIC通常很針對特定的演算法,設計的工程師只需要考慮較少的變數。要設計一個為了單一運算的電路,工程師只需要簡單的把計算轉換成線圈且針對其做優化。但如果要設計一個多功能的電路,工程師需要預測哪一種電路可以在各種任務下表現得都很好,而且這些任務可能是無法事先預測的。
一個AI晶片的商業化很看重他通用的能力,像GPU就已經高度商業化很久了,同時ASIC也比較難商業化因為他們的設計成本和低產量。然而,特製的晶片相對的也有他商業價值因為他們的產品生命週期較長。在目前CPU低成長的年代,如果AI晶片能夠實現10~100倍的加速,那只需要賣15000~83000個就可以有足夠的商業價值。這個市場的成長有機會可以讓ASIC這種更專精的晶片有獲利空間。
AI的晶片有很多種等級,最高等級的伺服器級AI通常被用在資料中心拿來做高階應用,中階的用於一般電腦,最低階的用於行動裝置上用來推論且多半和CPU一起混用。行動裝置的晶片需要輕量化來放在行動裝裝置上使用。在這些等級中,AI晶片的市場都越來越大。
超級電腦有一定的限制但和AI越來越相關,最常見用於伺服器的晶片可以執行grid computing,一台超級點腦使用好幾個伺服器級晶片,集中放在一起並使用冷卻的裝置來避免過熱,這個設定有助於提升速度但嚴重影響到效率,這是為了做一些快速分析可接受的妥協,現在很少AI應用適合用額外的花費來提升速度,但一個大型AI演算法的訓練過程有時候會需要太久所以最終還是會使用到超級電腦。因此,雖然傳統上超級電腦都使用CPU,但AI晶片也佔一定比例,2018年GPU幾乎貢獻了所超級電腦新增加的計算效能。
AI晶片評分標準
目前工業上沒有一個通用的標準來比較CPU和AI晶片,因為通常晶片的比較會需要一個特定的基礎標準。然而對於每個節點來說,AI晶片比起CPU通常提供了10~1000倍的效能和速度進步,1000倍的效率相當於提供了26年CPU的進步,表2顯示我們對於AI晶片相對於CPU所提供的效率的預測。FPGA沒有效率和速度的數據,因為FPGA很少被用於訓練模型。
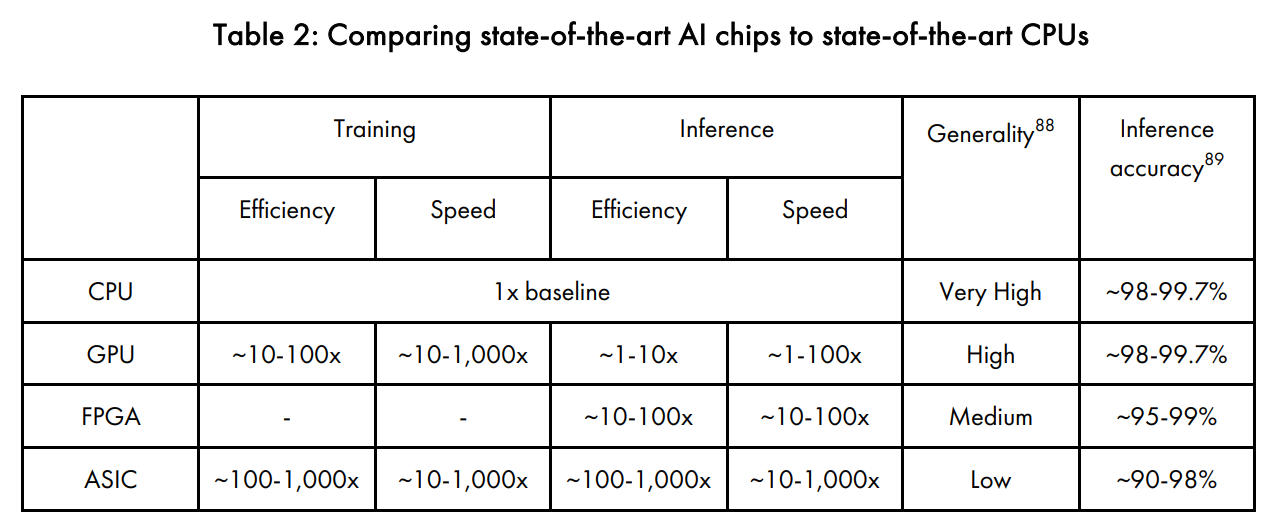
六、最先進的AI晶片的價值
AI晶片領先的節點對於要有效率且快速的訓練一個AI來說變得越來越必要,因為他們比CPU提供了更好的效率和速度,而且,如我們在前面提到的,效率最後也可以被想成是一個晶片的平均成本,尤其目前要訓練一個好的AI演算法所遇到的瓶頸就是效率和速度。
最先進的AI晶片如何降低成本
效率可以轉化成整體節省的成本,對於比較落後的晶片來說,晶片運作時花費的能源成本是晶片主要的成本且會迅速的提高到難以掌控的程度,即便是最新的節點,運行成本通常和生產成本差不多,也就意味著繼續優化效能是必要的。
表三呈現了晶片生產和運行成本從90nm到5nm用相同數量的電晶體的CSET經濟模型。目前像google這種公司都使用自己設計以後,交由台積電等晶圓廠做製造的流程。
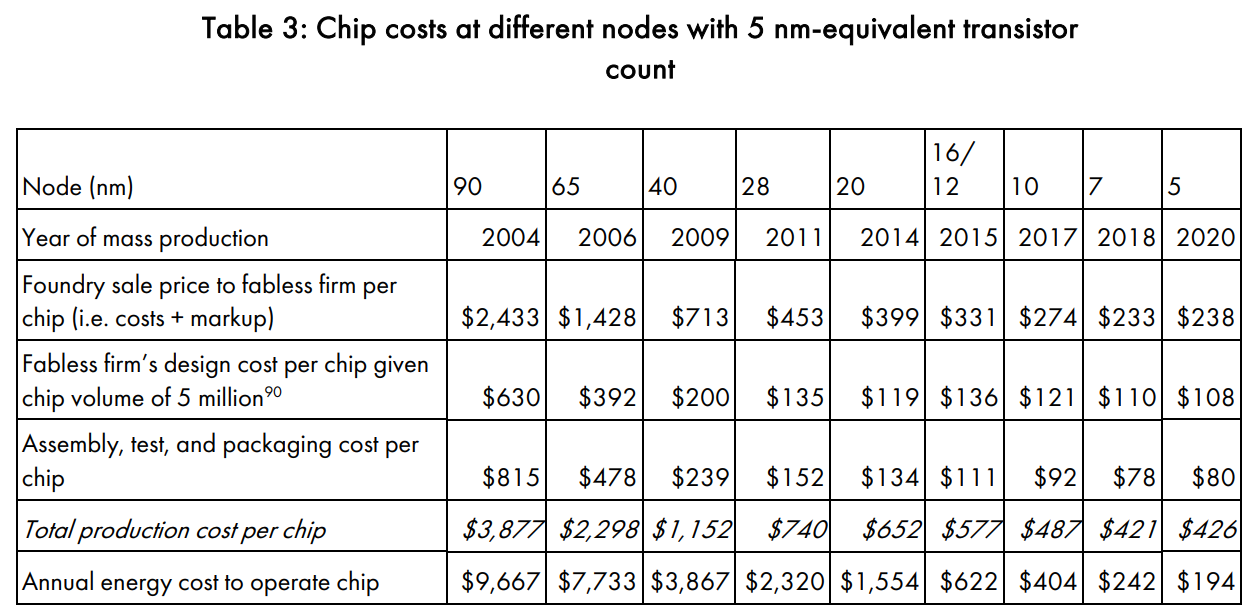
成本可以被拆解成以下幾塊,晶圓廠需要負擔建造硬體設備和材料等成本,而沒有晶圓廠的公司則承擔設計成本。受到委託的半導體業者負責組裝、測試、打包晶片。這些成本加起來等於製造一個晶片的成本,沒有晶圓廠的企業還要在運行的時候負擔能源消耗的成本,我們用每千瓦小時0.07美元來估計能源成本,做出了兩個結論:
第一,最近兩年內,使用較新節點的晶片(7或5奈米)的成本超過製造舊的成本,而用比較舊的AI晶片運作成本是製造那些晶片成本的3~4倍。從圖8我們可以知道考慮製造和運行成本後,最新的AI晶片的效率比舊晶片好了33倍。
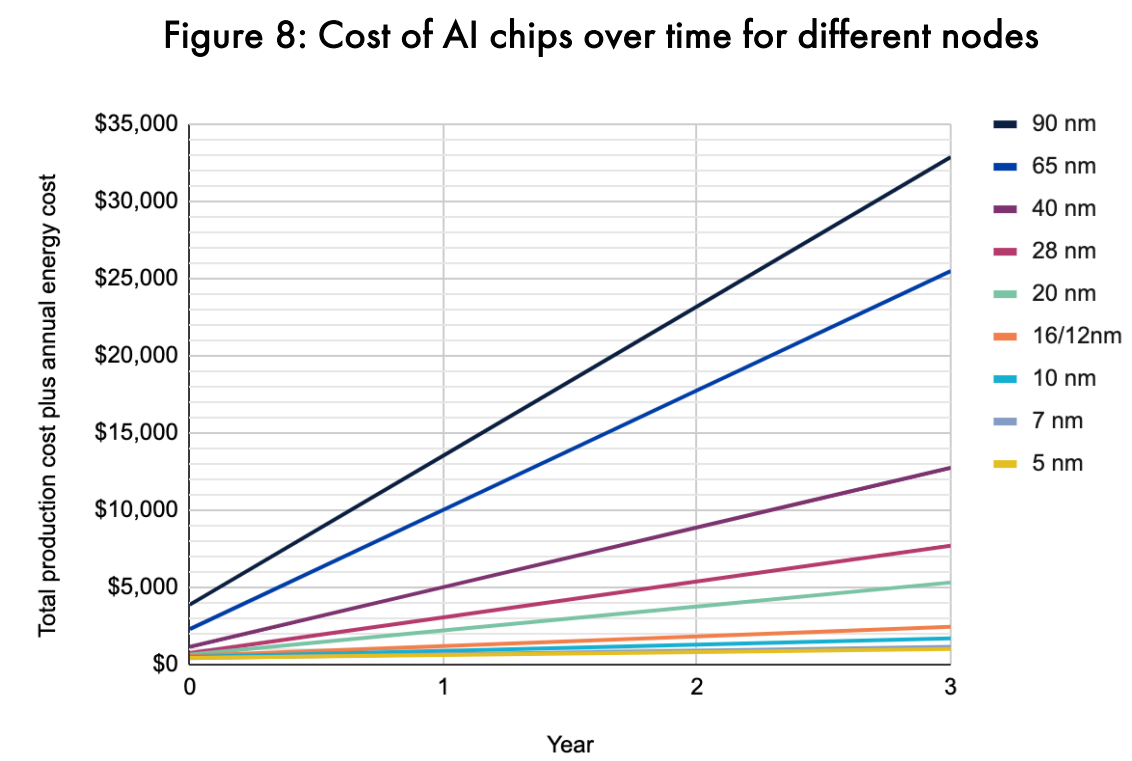
第二,要製作5nm晶片並使用它的平均成本如果要低於使用7nm晶片,必須要花8.8年來均攤,低於8.8年,使用7nm晶片是較便宜的。因此,用戶至少需要有使用8.8年以上的準備,才理由更換現存的7nm晶片。企業通常每三年就會更換伺服器等級的晶片,和最近新節點出現的頻率是吻合的,也就是企業通常在新節點出現後就會盡快更換舊有晶片,然而對於5nm的晶片來說,他們可能會預期這些晶片要使用久一點,這也讓市場預測3nm的晶片會很久過後才會被引進。
AI演算法的瓶頸在晶片成本和速度
AI企業在AI相關計算所花費的時間和成本已經變成AI成長的瓶頸,這些AI實驗室因此需要最好的AI晶片。
首先,DEEPMIND最先進的AI研究如ALPHAGO等,每個案子預估要500萬~1億美元,有一份成本評估報告說ALPHAGO ZERO的訓練成本是3500萬美元。OPENAI的財報顯示他們2017年2800萬的支出中有800萬用在雲端運算,這些計畫如果使用CPU或其它舊版的AI晶片,可能就會讓這些研究無法進行,而且很多AI公司的計算成本都在迅速地提高,很快就會到達可負荷的上限,因此高效的AI晶片是必要的。
再來AI實驗可能會需要幾天甚至好幾個月來做訓練,而部署一個重要的AI系統需要即時且快速的推論系統,使用舊版的晶片或者新的CPU,都會讓這些實驗的進行過於緩慢。使用較慢晶片之公司可能會試圖消耗大量的資源來使用這些晶片做平行運算,但這行為注定會失敗。因為一次要操作太多的AI晶片會讓工程師在處理平行運算時遇到困難,而且即便工程師設計出了能夠大量平行運算的演算法,這樣的演算法也會需要很多輔助軟體和網路技術來完成。要讓上千個GPU平行運算是非常難的事情,如果是用舊版的GPU那就更不用說了。新的Cerebras Wafer Scale Engine晶片就是讓很複雜的平行運算可以在單一晶片上完成,不需要再借助進階的網路科技。
七、美國和中國AI晶片的比較及國際間競爭關係的影響
AI晶片的優劣在政治因素上來看是很重要的,美國公司目前主宰了AI晶片設計,而中國公司遠遠的落後,且很依賴美國的EDA軟體來設計晶片,也需要美國和他們的盟友的SME和晶圓廠來協助製作。頂級的AI晶片價值和其生產線重要的部分多數集中在美國陣營這件事,讓他們有足夠的支點來確保AI科技發展的領導地位。
美國的Nvidia和AMD兩間公司掌握了世界的GPU市場,而中國頂尖的GPU公司Jingjja Microelectronics遠遠的落後。在FPGA市場上,XILINX和INTEL也大幅領先。ASIC市場方面,由於設計成本較低,特別是推論模型專用的,目前進入障礙較小,不像GPU和FPGA,一些致力於AI研究的公司如GOOGLE、TESLA、AMAZON都開始設計自己AI應用專用的ASIC。而中國的公司雖然也在ASIC方面雖然也有投入,但他們的應用多半很侷限於推論模型。
表4是目前美國和中國生產的伺服器等級晶片比較,它顯示出了兩件事:
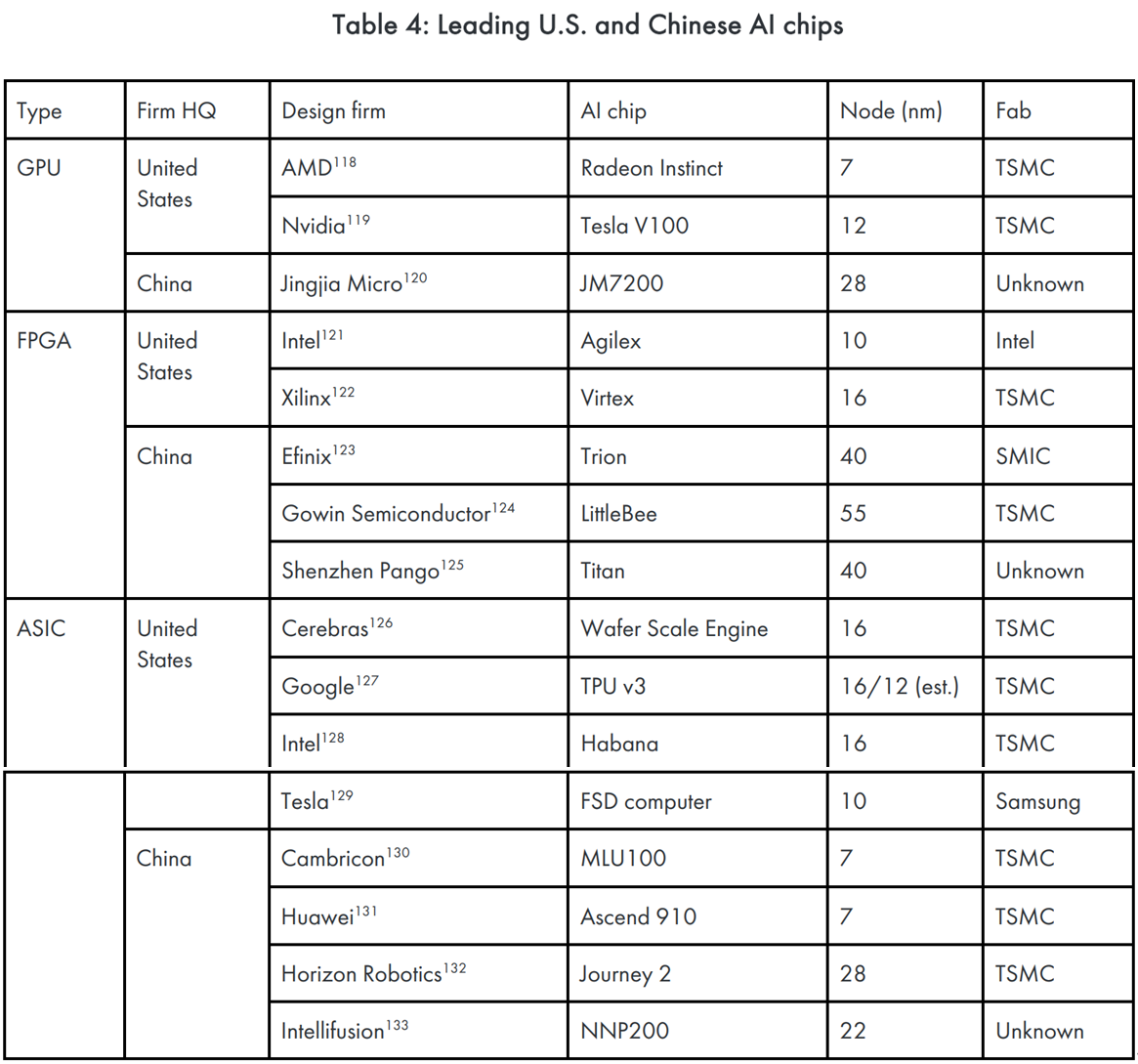
首先,美國企業的AI晶片合作的晶圓廠多半是台積電、三星、INTEL等技術領先的公司。美國的GPU比FPGA和ASIC或許因為他們的通用性更頻繁地被使用。專家對於AI節點是否需要用領先的節點意見並不一致,一個EDA公司的執行長說:所有要做AI研究的人都需要7nm以下的效能。但一個香港的半導體研究員說:使用28nm的技術製造AI晶片的成本比起10或14nm低很多,因為很多數學、物理、程式碼方面的問題需要解決表四的資料說明了這個問題,所有我們調查的美國AI晶片都使用接近最新節點的晶片(<=16nm),這個資料和CSET晶片經濟模型的結果是相符的,而且用16nm以下的晶片是最有經濟效益的。只有少數的晶圓廠有能力製造最新等級的AI晶片,全世界大概只有8.5%的晶圓廠可以被用來製造這種晶片,且只有部分正在被用於製造他們,這個數據每年都在浮動所以並不好計算。
第二,中國的AI晶片製造公司在GPU和FPGA使用較落後的節點,而ASIC方面則新舊混雜,即便中國有些本土的晶圓廠有能力製造這些晶片,但這些公司多半還是委託台灣的台積電等晶圓廠代工,這或許顯示了TSMC的製程比起中國企業來的更可靠。總體而言,中國在AI晶片製造方面的能力還是非常依賴美國。
中國在設計AI推論用的ASIC方面已經相當成功,因為他們大量的研發人數非常適合這種需要大量人力的晶片開發上,然而,由於中國的晶片設計產業相對來說非常年輕,他們還尚未能夠掌握GPU和FPGA的開發技術。
中國的公司在他們的設計中也很大程度的依賴西方的IP核心,例如華為就使用ARM的指令集和IP核心。中國的FPGA製造者也使用INTEL和XILINX的FPGA IP核心。IP核心的費用也隨著晶片的技術指數型的上升。
中國很缺少AI晶片供應鏈中核心技術的發展,包括設計、EDA軟體、SME和晶圓廠,也就代表美國及其盟友國在最尖端的AI晶片上的兢爭優勢非常大,而這些尖端AI晶片技術又在與安全相關AI系統之發展及應用中有關鍵的戰略價值,因此,對於美國及其盟友,以及全球的安全而言,在接下來如何維持這項優勢是非常重要的。
(摘譯:黃則普)
上篇:https://www.aili.com.tw/message2_detail/111.htm